

AI-IoT Topic Guides for Product and Engineering Decisions
Use these guides to choose a practical implementation path across IoT platforms, edge gateways, industrial protocols, AI automation, private knowledge bases, and AI vision.
Read by implementation problem
Each page links to related services, products, and AI technology pages so the guide can lead into action.
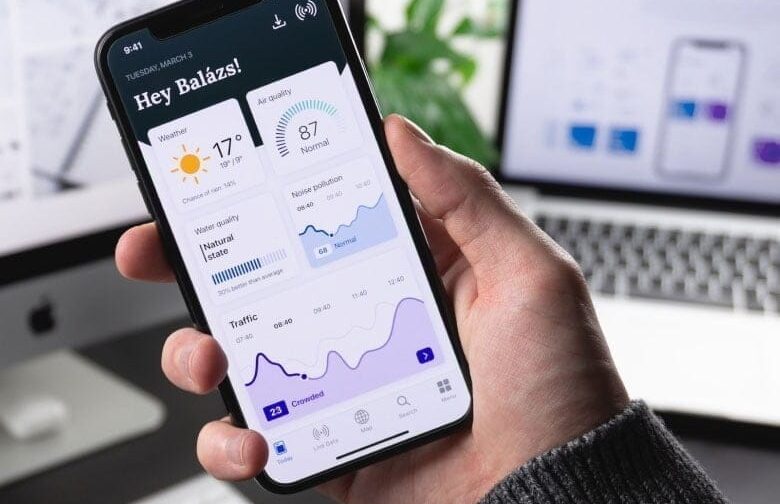
Connected systems and operations
Start here when the project is blocked by device access, telemetry, protocol, gateway, or operations-platform decisions.

AI workflows and private intelligence
Use these guides for enterprise AI applications, private knowledge, Agent orchestration, vision, and voice workflows.

Embedded intelligence and industry use
Evaluate device-side compute, smart-home integration, TinyML, and industrial data paths before choosing hardware or software.
Start from the constraint that blocks the project
If the problem is field connectivity, start with gateway and protocol topics. If the problem is internal productivity or customer workflow, start with AI automation and private knowledge-base topics.
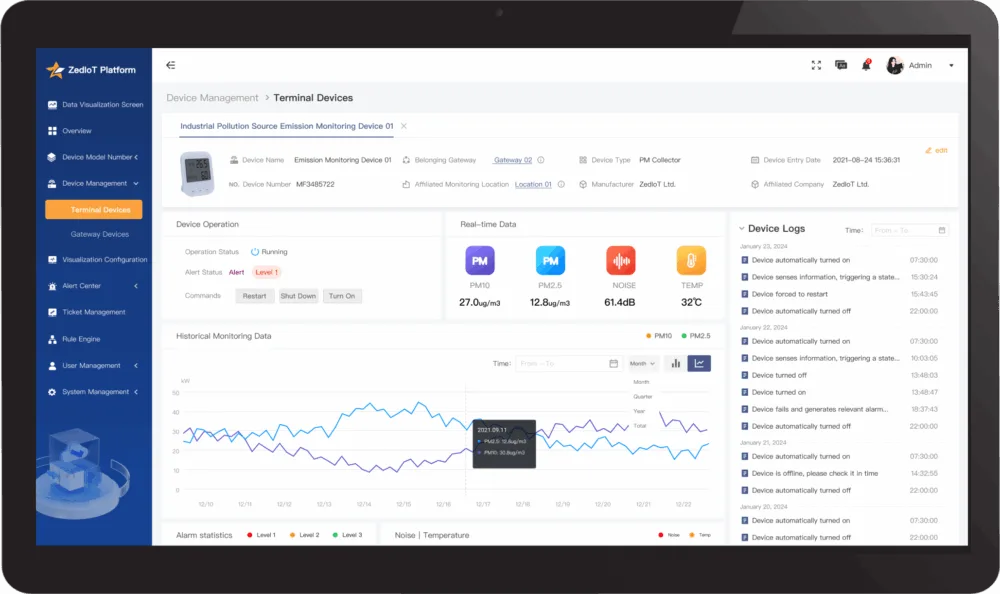
Device and data foundation
Platform, gateway, protocol, telemetry, and remote operations decisions.
AI workflow foundation
AI apps, agents, RAG, automation, vision, and deployment decisions.
Continue into a service, product, case, or deeper technical article
The guides explain the decision. These paths show how ZedIoT can help implement it, what product foundation is available, and where similar work has been delivered.
Need help choosing the right path?
Send the equipment type, workflow pain point, target systems, and current data status. We will suggest a practical first implementation direction.
- AI + IoT product architecture review
- Hardware, firmware, cloud, and application integration
- Prototype planning and production support